T.E.S.S.
Text Entry Suggestion System
Project Details
- Category: Data Science
- Date: April 2023
- Mark: 19/20
- Language: C with GTK
- GitHub: Project Repository
- Project Report (in French)
TESS (Text Entry Suggestion System) is born from a collaborative work between Kawtar El Mamoun and myself. Our main objective was to create a human-machine interface that provides suggestions for incomplete user input. For this, we chose to implement hash tables. TESS should also be capable of capturing and storing entered words as well as the most frequently used words. Spelling will be systematically checked, and the user will have the option to add names and acronyms.
Presentation
Intuitive Input
The goal of the project is to create a human-machine interface that provides suggestions for incomplete user input. The implemented application should also be capable of capturing and storing entered words as well as the most frequently used words. Spelling will be systematically checked, and the user will have the option to add names and acronyms.
Instructions
The application should be able to facilitate interaction between the user and the program through a user-friendly interface in the C language, allowing for:
Resources
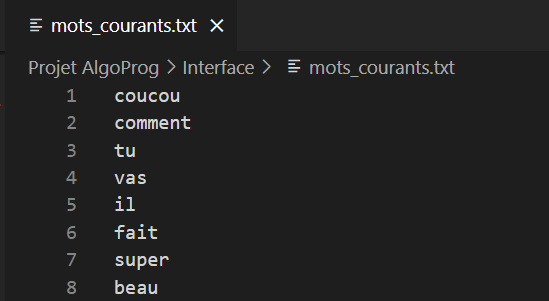
An initial prediction dictionary is available on the school's Intranet, and we have also imported a dictionary of all words in the French language.
Interpretation
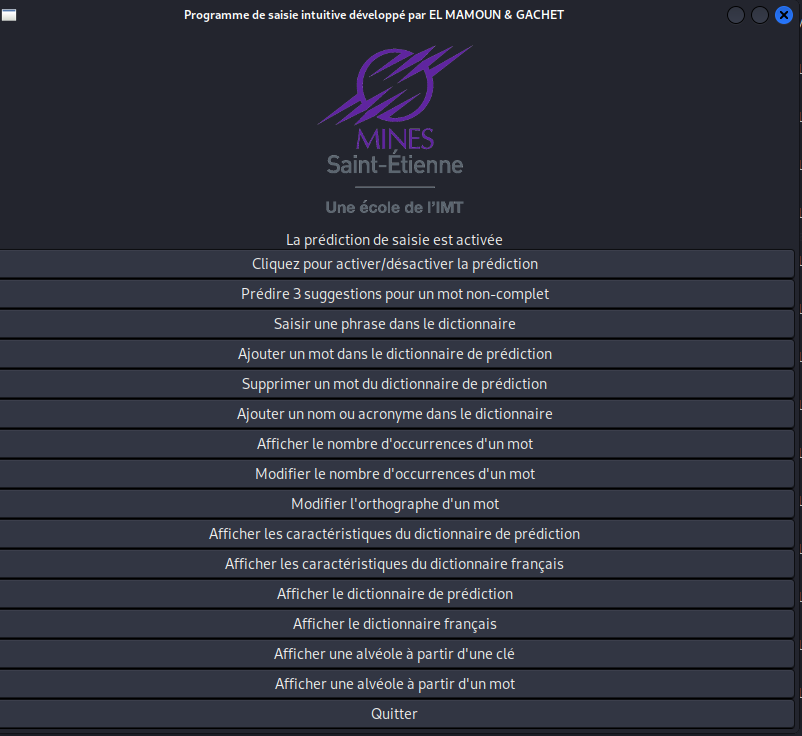
In order to create a user-friendly program, we have chosen to develop two types of interfaces:

Data Structures Used
Hash Tables
We will extract the words provided by the file mots_courants.txt and store them in a hash table for quick and efficient access. Indeed, hash tables provide an average access time of O(1), regardless of the number of key-value pairs in the table. A hash table is a data structure that efficiently stores elements and allows for fast retrieval. It is used in many applications, including compilers, databases, and search algorithms. The operation of a hash table in C can be summarized in a few steps:
It is important to note that choosing a good hash function is crucial to optimize the performance of a hash table in terms of data access time. Additionally, it is often necessary to resize the hash table based on the number of stored elements to maintain a uniform data distribution.
Linked Lists
A linked list is a data structure that allows for dynamic and efficient storage of a sequence of elements. Unlike arrays, linked lists can be easily resized without having to move all the elements in memory.
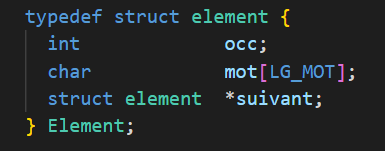
A linked list consists of nodes (or elements) that each contain data and a pointer to the next node in the list. The first node of the list is called the head of the list, and the last node is typically terminated by a NULL pointer. It is important to note that the structure of linked lists in C can be used to implement other data structures, such as stacks, queues, binary trees, etc. The structure of a node for our linked lists is defined as follows:
Modularity and Code Structure
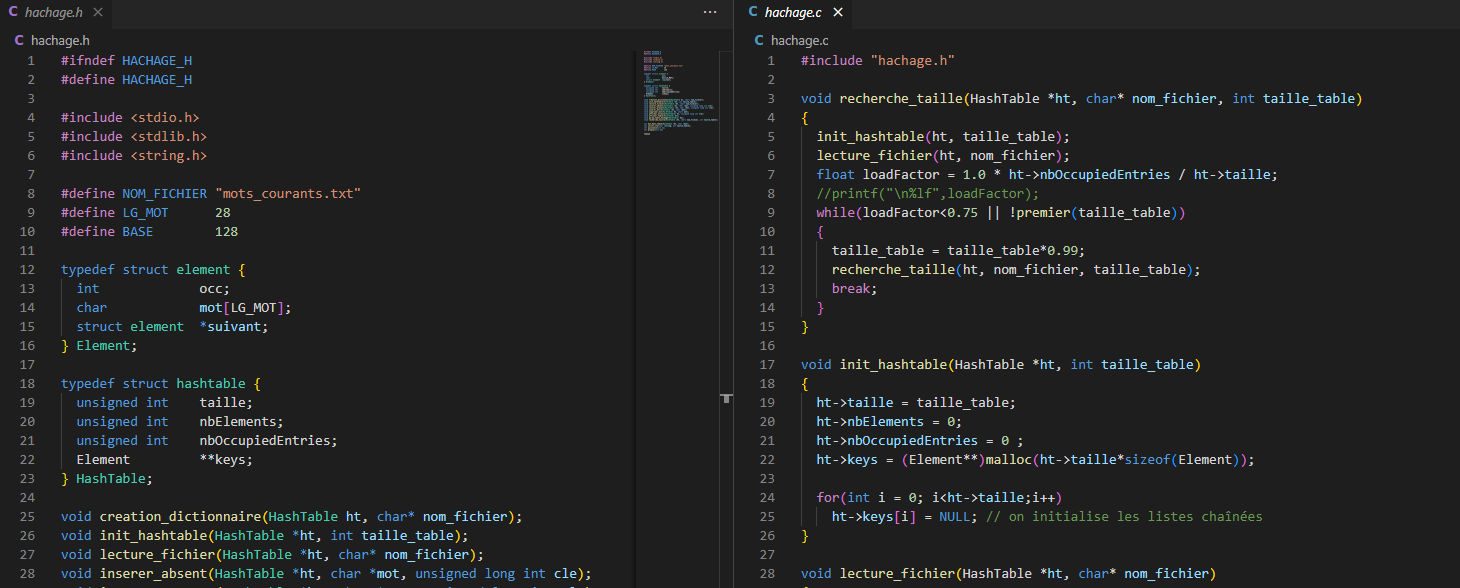
The modularity of the project is detailed in the README file. Our program is divided into 3 modules, as well as a main.c file. The first module (hachage.h | hachage.c) concerns the structure of the hash table used in this program, along with the prototypes and associated functions.
The second module (liste.h | liste.c) details the structure of our linked lists and the useful functions for their manipulation.
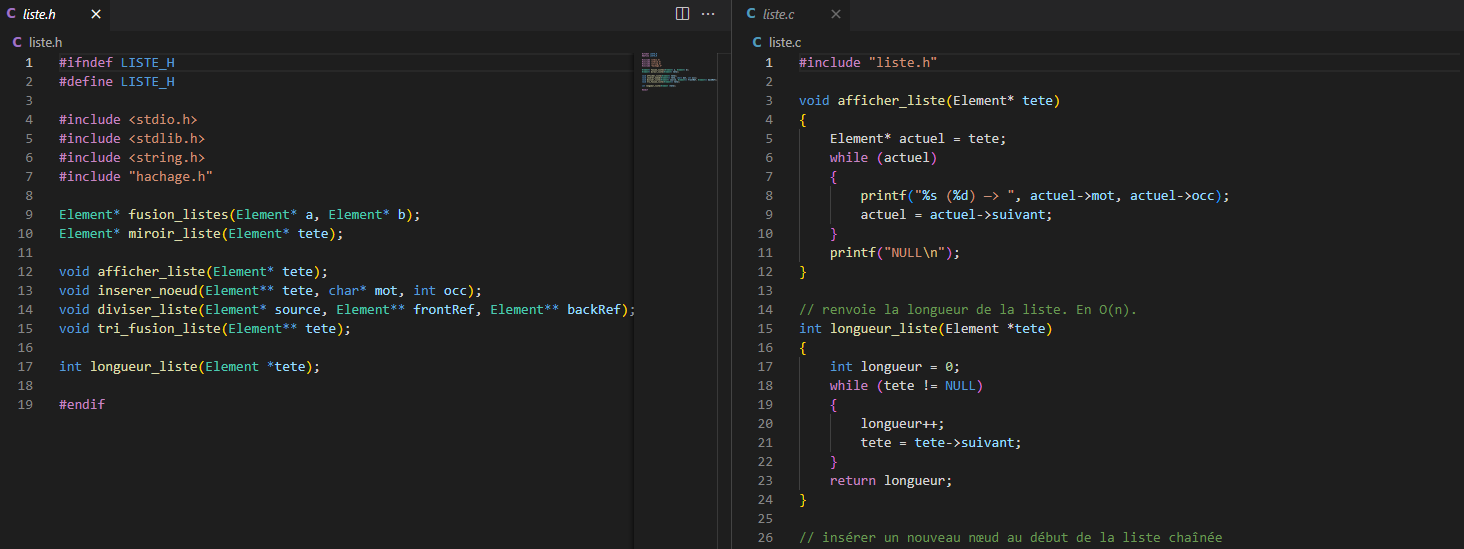
Finally, the module (user.h | user.c) consists of the functions constituting the main menu and assigns the functions that the user will directly call when interacting with the interface.
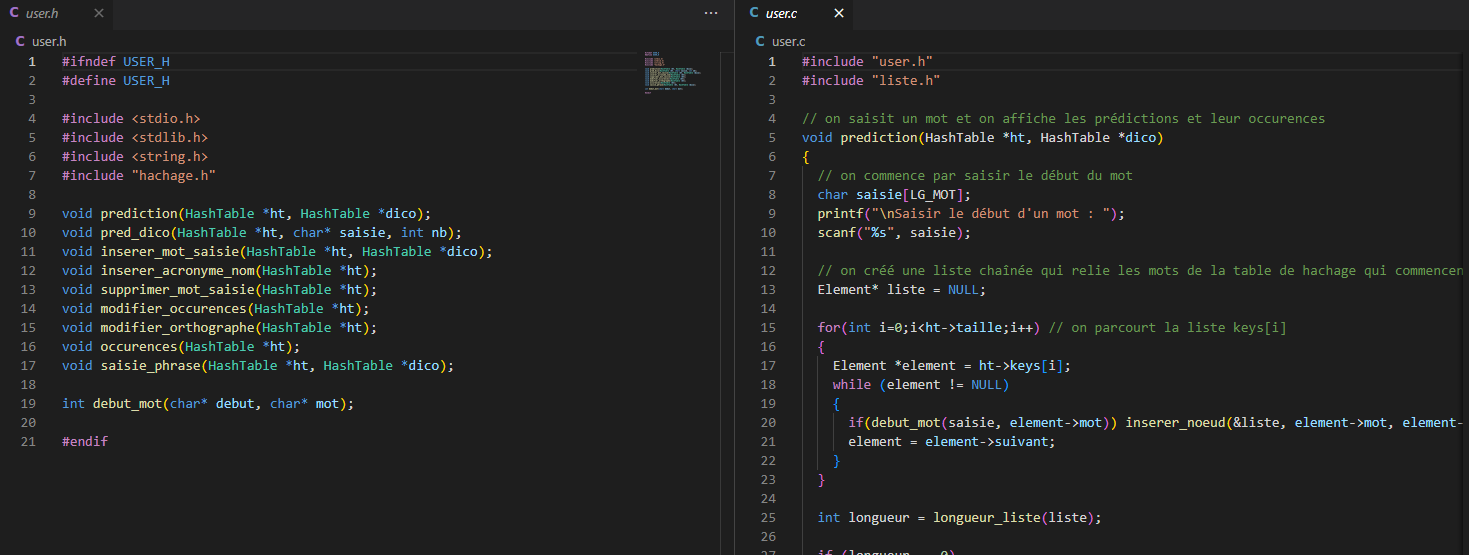
Proposed Algorithms
Note: You will find later the list of implemented functions along with a brief description for each of them. Furthermore, they are explained in the code.
Hash Table Management
First, the hash table is initialized as an array of empty slots (containing empty linked lists, i.e., NULL). Then, lecture_fichier() is used to fetch the words to be imported and adds them to the hash table based on their key calculated using the hash function. Meanwhile, the function recherche_taille() iterates the process until obtaining hash parameters that provide an optimal load factor, i.e., close to 0.75.
Input Prediction
The function prediction() prompts the user to enter a word and returns 3 suggestions to complete it. The suggestions come from the prediction dictionary built from the mots_courants.txt file but can be supplemented by the French dictionary in case the initial file does not provide enough suggestions. The user enters the beginning of a word, and an empty linked list is created to store the corresponding suggestions. The hash table is then traversed, searching for words for which the debut_mot() function returns 1 (if the two words have the same beginning), and the relevant words are added to the list.
The node structure of a linked list contains the spelling of the word as well as its occurrence, i.e., the number of appearances. Various manipulations on linked lists (merge, reverse, merge sort) are used to order the linked list containing all possible predictions in descending order of occurrences in the hash table. Then, by selecting the first 3 nodes from the linked list, the 3 suggestions with the highest number of occurrences in the prediction dictionary can be determined. The pred_dico() function completes these suggestions in case there are not enough of them.
Adding and Deleting a Word or Acronym
To add a word to the hash table via inserer_mot(), the key for the word is calculated using calcul_cle(). Then, the function mot_dans_table() indicates whether the word is already present in the prediction dictionary or not. Two options are possible:
To delete a word, it is checked whether it is present in the prediction dictionary. If so, its node in the corresponding slot (accessible via the key) is removed.
Inputting a Sentence
When the user inputs a sentence, they enter words separated by a space. The program will segment the input sentence into a matrix (i.e., an array of arrays since a string is essentially an array) in order to apply the inserer_mot() function to each element of the sentence.
Orthographic Modifications
The statement mentioned "modifying" a word. Therefore, we interpreted this as a word being able to change its spelling. In practice, if mot1 needs to be modified to mot2, then we add mot2 to the hash table, initialize its number of occurrences to be equal to that of mot1, and then delete mot1.
Characteristics of Hash Tables
For various reasons, often optimization-related, the user may want to view the characteristics of a hash table, whether it be the prediction dictionary or the French dictionary. Thus, we display the load factor, the number of words, the total number of slots, and the number of occupied slots.
Displaying Slots
The user has the option to view a specific slot by entering a word or directly entering a key. We then display all the words with the same key, along with their frequency of occurrence in the following format:
Displaying Hash Tables
The user has the option to view the entire hash table. In reality, this means displaying all the slots in the hash table in the following format:
[0] -> word 0,1 (occ 0,1) -> ... -> word n,x (occ 0,x)
[1] -> word 1,1 (occ 1,1) -> ... -> word n,y (occ 1,y)
...
[n] -> word n,1 (occ n,1) -> ... -> word n,z (occ n,z)
Creating a Graphical Interface using GTK3
GTK is a software library that allows for the creation of, among other things, graphical interfaces like the one we want to develop.
y using GTK, we have created a user-friendly and interactive interface. We have implemented several widgets for display, including the window itself, the school logo, a button allowing the user to enable or disable intuitive input, associated with dynamic text to display this information. Finally, we have implemented an interactive menu that allows the user to launch the previously defined functions based on their choice.
Project Limitations and Proposed Solutions
Word Search
To predict the next word and display the 3 suggestions, we first need to traverse the entire hash table and store the words in a linked list. Although we have implemented a merge sort algorithm to efficiently sort this linked list, the traversal of the hash table could still be improved.
Prefix Trees
To address the issue posed by the traversal of the hash table, one possible solution is to implement a heap, and in particular, a prefix tree appears to be suitable for our problem.
Realism of Text Prediction
For more advanced predictive input algorithms like those used by Google, additional features are implemented to complete real-time input. Search engines use history and user habits to predict the next part of their input, which we have implemented in our program. However, this alone is not enough to predict the user's expectations correctly and precisely.
Search engines analyze the context of the user's query and based on popular searches associated with that query, provide multiple choices. Language models (LM) allow the machine to analyze this by relying on the frequency of occurrence or usage of a large number of words. In our program, a simplified version is implemented, which increments the frequency of occurrence and the number of occurrences of a word based on the user's input.
Results Interpretation
Optimization of the Hash Table
Load Factor
We have programmed the creation of the prediction dictionary as a dynamic hash table. The size of the table influences the hash key, and the key influences the filling of the slots. Additionally, this filling, along with the total number of slots, contributes to calculating the load factor. Since these parameters are interdependent, we have developed the recherche_taille() function to obtain an optimal value for the size of the hash table and thus achieve a load factor close to 0.75.
Hash Function
In the code, we calculate the key of a word as follows:
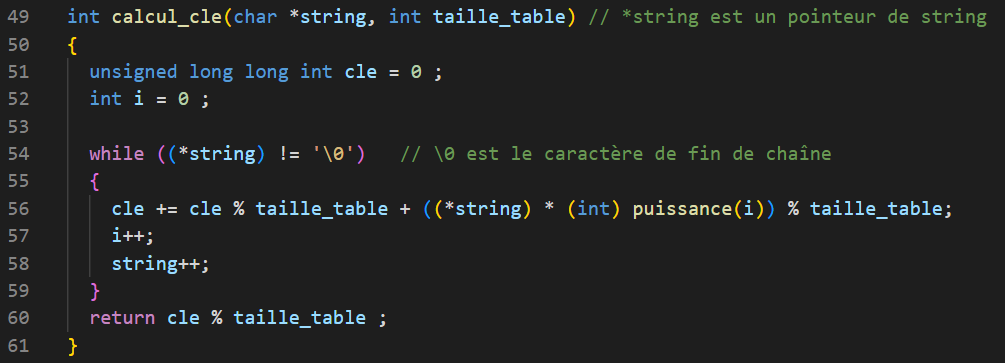
Thus, the hash function allows us to obtain the key of mot as follows:
We initialize nb_letters = n and cle(0) = 0 and for all integer i in [1,n]:
Using the Program on the Terminal
To run the code with the terminal interface, execute the following commands:
./all_without_interface
Using the Program with GTK3 Interface
To run the code with the graphical interface developed using GTK, you will need to install the gtk library:
apt-get install libgtk-3-dev
Once the library is installed, you can display the interactive interface by executing the following commands:
./all_w_interface
Detailed Functions Description
For the Hash Table
void init_hashtable(HashTable *ht, int size_table);Allocates memory and initializes the hash table as an array of a predefined size filled with empty linked lists (NULL).
int calcul_cle(char *string, int size_table);Calculates the key of a word.
void recherche_taille(HashTable *ht, char* nom_fichier, int size_table);Optimization function that searches for the optimal size of a hash table.
int mot_dans_table(HashTable *ht, char *mot);Returns 1 if a word is in the table, 0 otherwise.
void inserer_absent(HashTable *ht, char *mot, unsigned long int cle);Inserts the first occurrence of a word into the hash table.
void inserer_present(HashTable *ht, char *mot, unsigned long int cle);Increases the occurrence of a word in the hash table.
void inserer_mot(HashTable *ht, char *mot);Inserts a word into the hash table.
void supprimer_mot(HashTable* ht, char* mot);Removes a word from the hash table.
void lecture_fichier(HashTable *ht, char* nom_fichier);Reads the file provided as an argument and inserts each word into the hash table.
void afficher_alveole(HashTable* ht, unsigned long int cle);Displays a slot of the hash table based on the provided key.
void afficher_table(HashTable* ht);Displays the entire hash table.
void param_table_hachage(HashTable* ht);Displays the characteristics of a hash table.
int puissance(int i);Returns the base for the calculation raised to the power of i (for the hash function).
int premier(int n);Returns 1 if n is prime, 0 otherwise.
For Linked Lists
void diviser_liste(Element* source, Element** frontRef, Element** backRef);Splits a linked list into two approximately equal parts and puts the nodes of each part in different pointer-to-pointer variables.
Element* fusion_listes(Element* a, Element* b);Takes two lists sorted in ascending order and merges their nodes to form a larger sorted list (which is returned).
Element* miroir_liste(Element* tete);Returns the reverse of a linked list. O(n) time complexity.
void tri_fusion_liste(Element** tete);Sorts a linked list using the merge sort technique.
void inserer_noeud(Element** tete, char* mot, int occ);Inserts a new node at the beginning of the linked list.
void afficher_liste(Element* tete);Displays a linked list.
int longueur_liste(Element *tete);Returns the length of the list. O(n) time complexity.
For the User
int debut_mot(char* debut, char* mot);Returns 1 if "mot" starts with "debut", and 0 otherwise.
void prediction(HashTable *ht, HashTable *dico);The user enters a word, and the 3 predictions with the highest occurrences in the prediction dictionary are suggested. If the number of suggestions from the prediction dictionary is less than 3, then suggestions from the French dictionary are added to complete the list.
void pred_dico(HashTable *ht, char* saisie, int nb);Displays nb suggestions starting with "saisie" from the French dictionary.
void inserer_mot_saisie(HashTable *ht, HashTable *dico);The user enters a word, and it is added to the hash table. If the word is already in the hash table, its "occ" value is incremented. The addition of a misspelled word (absent from the French dictionary) is not possible.
void inserer_acronyme_nom(HashTable *ht);The user enters a word, and it is added to the hash table. If the word is already in the hash table, its "occ" value is incremented. The addition of a misspelled word (absent from the French dictionary) is possible.
void saisie_phrase(HashTable *ht, HashTable *dico);The user enters a sentence, and the words, separated by spaces, are inserted into the prediction dictionary.
void supprimer_mot_saisie(HashTable *ht);The user enters a word, and it is removed from the hash table.
void occurences(HashTable *ht);The user enters a word, and the function displays its number of occurrences.
void modifier_occurences(HashTable *ht);The user enters the word for which they want to modify the number of occurrences and the new value, and the modifications are made.
void modifier_orthographe(HashTable *ht);The user enters the word "mot1" for which they want to change the spelling to "mot2". "mot2" is then added to the hash table, and its occurrence count is set to the count of "mot1". Then "mot1" is removed from the hash table. In a way, "mot1" has passed its occurrences to "mot2" before disappearing.
For the Graphical User Interface (GTK)
The following functions were used to develop the interactive graphical interface. Their names are self-explanatory, and their role is mainly to structure the design of the interface. It is unnecessary to delve into their operation:
void option_quitter(GtkButton *button, gpointer data); void option_activer(GtkButton *button, gpointer data); void option_predire(GtkButton *button, gpointer data); void option_saisir_phrase(GtkButton *button, gpointer data); void option_ajouter_mot(GtkButton *button, gpointer data); void option_supprimer_mot(GtkButton *button, gpointer data); void option_ajouter_acronyme(GtkButton *button, gpointer data); void option_afficher_occurrences(GtkButton *button, gpointer data); void option_modifier_occurences(GtkButton *button, gpointer data); void option_modifier_orthographe(GtkButton *button, gpointer data); void option_caract_dico_pred(GtkButton *button, gpointer data); void option_caract_dico_fr(GtkButton *button, gpointer data); void option_afficher_dico_pred(GtkButton *button, gpointer data); void option_afficher_dico_fr(GtkButton * button, gpointer data); void option_alveole_par_cle(GtkButton *button, gpointer data); void option_alveole_par_mot(GtkButton *button, gpointer data);